
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 패킷 필터링
- 기업용백신
- selenium
- AWS
- phpwrapper
- 빈칸넣기
- 보안
- Security
- aws network firewall
- 인터넷게이트웨이
- 네트워크 방화벽
- 방화벽
- aws firewall
- 표 크롤링
- apex central
- VGG19
- 파이썬
- Firewall
- VPC
- AWS 클라우드
- Crawling
- Network firewall
- 크롤링
- 클라우드
- 리스트
- 테이블 크롤링
- apex one
- 위협탐지
- python
- 웹크롤링
- Today
- Total
민주의네모들
[python] Selenium으로 웹 페이지 크롤링하기 1 / 평문(text) 본문
1. Selenium 이란?
이번 포스팅에서는 selenium이라는 프레임워크를 통해 웹 페이지를 크롤링하는 방법에 대해 간단히 살펴보겠다.
Selenium이란 주로 웹앱을 테스트하는 웹 프레임워크이다.
webdriver의 API를 통해 브라우저를 제어하기 때문에 자바스크립트에 의해 동적으로 생성되는 사이트의
데이터를 크롤링할 때 매우 유용하게 사용되는 스크래핑 도구이다.
2. Selenium 사용법
selenium은 크롬이나 파이어폭스같은 각 브라우저의 webdriver API를 통해 브라우저를 제어한다.
따라서 자신이 쓰고자 하는 브라우저의 driver를 다운받아서 프로그래밍 언어를 통해 제어하는 것이 일반적이다.
나는 크롬을 주로 사용하기 때문에 chromedriver를 먼저 다운받도록 하겠다.
https://chromedriver.chromium.org/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
chromedriver.chromium.org
여기서 chromedrvier를 다운받을 수 있는데 여기서 주의해야 할 점은,
자신의 pc에 있는 크롬 브라우저의 버전에 맞는 driver를 다운로드 받아야 한다는 것이다.

이렇게 여러가지 버전이 있으니 자신의 크롬 브라우저 버전을 확인 후, 버전에 맞는 driver를 다운받는다.
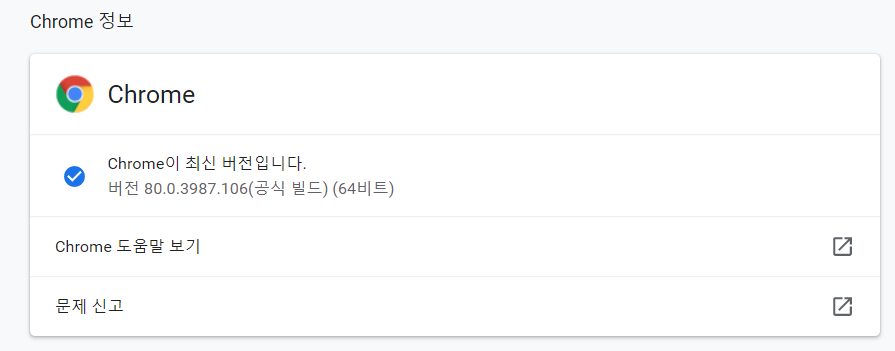
(크롬 버전은 메뉴> 도움말> Chrome 정보 에서 확인이 가능하다.)
(혹시 최신 버전이 아니라면 이 기회에 최신 버전으로 업데이트 해보자!)
그렇게 해서 다운로드 받은 알집 파일의 압축을 풀면 chromedriver.exe 파일이 나온다.

이 파일을 내가 작업할 디렉토리에 넣는다.
그리고 selenium을 설치해야 하는데, 늘 그렇듯 터미널에서 pip 명령어로 다운받아 준다.
나는 예전에 설치를 해놓았기 때문에 already satisfied라고 떴다.
그럼 이제 코딩을 시작하면 된다!
3. 파이썬을 통한 크롤링 방법 (feat. Selenium)
from selenium import webdriver
import datetime
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(1)
driver.get('https://minjoos.tistory.com/')기본 세팅은 여기까지이다.
먼저 import 해줘야 할 것들을 Import 해주고,
마지막 줄에 본인이 크롤링 하고 싶은 웹 페이지의 url을 넣어준다.
(implicity_wait()은 브라우저에서 사용되는 엔진 자체에서 파싱되는 시간을 기다려 주는 메소드라고 할 수 있다.
시간이 오래 걸리는 작업일수록 적절히 중간중간에 Implicity_wait()를 넣어주는게 좋다.)
여기까지 하고 실행을 시키면 'Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다'라는 문구와 함께
url로 넣어주었던 웹 페이지가 실행된다.

이제 개발자 도구를 통해 자신이 얻고 싶은 정보의 위치가 어디인지 파악한 다음, 코드에 넣는 작업을 해보겠다.
F12를 눌러 개발자 도구를 실행시키면, 페이지를 구성하고 있는 코드가 보인다.

그 중에서 맨 왼쪽 상단 버튼을 클릭하면 자신이 커서를 놓는 위치의 코드로 바로 이동할 수 있다.

위 사진의 개발자도구 창을 보면 '민주의네모들'에 해당하는 위치의 class 이름이 "tit_post"임을 확인할 수 있다.
title = driver.find_element_by_class_name('tit_post')
print(title.text)따라서 find_element_by_class_name() 메소드를 통해 title에 해당 정보를 넣어주고,
title.text로 프린트를 해준다.
그리고 파일을 실행시켜주면,

제목이 잘 출력되는 것을 확인할 수 있다.
class이름 이외에도, XPath를 이용해 크롤링을 할 수 있다.

해당 위치의 코드에 마우스 오른쪽 버튼을 클릭해서 Copy>Copy XPath한 후,
코드에 다음과 같이 붙여넣는다.
title = driver.find_element_by_xpath('//*[@id="dkHead"]/div[2]/div/a')
print(title.text)이 때, 메소드는 find_element_by_xpath 이다.
그리고 파일을 실행시켜주면,

똑같이 잘 프린트 되는 것을 확인할 수 있다.
이를 활용해서 다른 요소도 프린트 해보겠다.

해당 XPath를 복사해서 코드에 넣어준 후, 파일을 실행시키면,

다음과 같이 잘 실행된다.
다음 시간에는 이렇게 하나의 text를 프린트하는 것 보다는
조금 더 심화된 내용인 table 크롤링 하기에 대해 포스팅하겠다.
'이모저모' 카테고리의 다른 글
| [python] Selenium으로 웹 페이지 크롤링하기 3 / 페이지 제어(blank에 값 입력, 버튼 클릭) (2) | 2020.03.11 |
|---|---|
| [python] Selenium으로 웹 페이지 크롤링하기 2 / 표(table) (7) | 2020.02.24 |

